3. Reverse Engineering a la Muth#
In addition to what’s in Anaconda, this lecture uses the quantecon library.
!pip install --upgrade quantecon
We’ll also need the following imports:
import matplotlib.pyplot as plt
import numpy as np
from quantecon import Kalman
from quantecon import LinearStateSpace
np.set_printoptions(linewidth=120, precision=4, suppress=True)
This lecture uses the Kalman filter to reformulate John F. Muth’s first paper [Muth, 1960] about rational expectations.
Muth used classical prediction methods to reverse engineer a stochastic process that renders optimal Milton Friedman’s [Friedman, 1956] “adaptive expectations” scheme.
3.1. Friedman (1956) and Muth (1960)#
Milton Friedman [Friedman, 1956] (1956) posited that consumer’s forecast their future disposable income with the adaptive expectations scheme
where
Milton Friedman justified the exponential smoothing forecasting scheme (3.1) informally, noting that it seemed a plausible way to use past income to forecast future income.
In his first paper about rational expectations, John F. Muth [Muth, 1960]
reverse-engineered a univariate stochastic process
Muth sought a setting and a sense in which Friedman’s forecasting scheme is optimal.
That is, Muth asked for what optimal forecasting question is Milton Friedman’s adaptive expectation scheme the answer.
Muth (1960) used classical prediction methods based on lag-operators and
Please see lectures Classical Control with Linear Algebra and Classical Filtering and Prediction with Linear Algebra for an introduction to the classical tools that Muth used.
Rather than using those classical tools, in this lecture we apply the Kalman filter to express the heart of Muth’s analysis concisely.
The lecture First Look at Kalman Filter describes the Kalman filter.
We’ll use limiting versions of the Kalman filter corresponding to what are called stationary values in that lecture.
3.2. A Process for Which Adaptive Expectations are Optimal#
Suppose that an observable
where
is an IID process.
Note
A property of the state-space representation (3.2) is that in
general neither
In general
We can use the asymptotic or stationary values of the Kalman gain and the one-step-ahead conditional state covariance matrix to compute a time-invariant innovations representation
where
Note
A key property about an innovations representation is that
For more ramifications of this property, see the lectures Shock Non-Invertibility and Recursive Models of Dynamic Linear Economies.
Later we’ll stack these state-space systems (3.2) and (3.3) to display some classic findings of Muth.
But first, let’s create an instance of the state-space system (3.2) then
apply the quantecon Kalman class, then uses it to construct the associated “innovations representation”
# Make some parameter choices
# sigx/sigy are state noise std err and measurement noise std err
μ_0, σ_x, σ_y = 10, 1, 5
# Create a LinearStateSpace object
A, C, G, H = 1, σ_x, 1, σ_y
ss = LinearStateSpace(A, C, G, H, mu_0=μ_0)
# Set prior and initialize the Kalman type
x_hat_0, Σ_0 = 10, 1
kmuth = Kalman(ss, x_hat_0, Σ_0)
# Computes stationary values which we need for the innovation
# representation
S1, K1 = kmuth.stationary_values()
# Extract scalars from nested arrays
S1, K1 = S1.item(), K1.item()
# Form innovation representation state-space
Ak, Ck, Gk, Hk = A, K1, G, 1
ssk = LinearStateSpace(Ak, Ck, Gk, Hk, mu_0=x_hat_0)
3.3. Some Useful State-Space Math#
Now we want to map the time-invariant innovations representation (3.3) and
the original state-space system (3.2) into a convenient form for deducing
the impulse responses from the original shocks to the
Putting both of these representations into a single state-space system is yet another application of the insight that “finding the state is an art”.
We’ll define a state vector and appropriate state-space matrices that allow us to represent both systems in one fell swoop.
Note that
so that
The stacked system
is a state-space system that tells us how the shocks
With this tool at our disposal, let’s form the composite system and simulate it
# Create grand state-space for y_t, a_t as observed vars -- Use
# stacking trick above
Af = np.array([[ 1, 0, 0],
[K1, 1 - K1, K1 * σ_y],
[ 0, 0, 0]])
Cf = np.array([[σ_x, 0],
[ 0, K1 * σ_y],
[ 0, 1]])
Gf = np.array([[1, 0, σ_y],
[1, -1, σ_y]])
μ_true, μ_prior = 10, 10
μ_f = np.array([μ_true, μ_prior, 0]).reshape(3, 1)
# Create the state-space
ssf = LinearStateSpace(Af, Cf, Gf, mu_0=μ_f)
# Draw observations of y from the state-space model
N = 50
xf, yf = ssf.simulate(N)
print(f"Kalman gain = {K1}")
print(f"Conditional variance = {S1}")
Kalman gain = 0.1809975124224177
Conditional variance = 5.524937810560442
Now that we have simulated our joint system, we have
We can now investigate how these variables are related by plotting some key objects.
3.4. Estimates of Unobservables#
First, let’s plot the hidden state
fig, ax = plt.subplots()
ax.plot(xf[0, :], label="$x_t$")
ax.plot(xf[1, :], label="Filtered $x_t$")
ax.legend()
ax.set_xlabel("Time")
ax.set_title(r"$x$ vs $\hat{x}$")
plt.show()
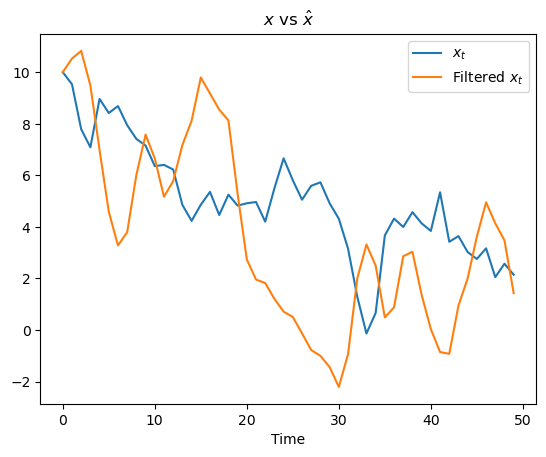
Note how
For Friedman,
3.5. Relationship of Unobservables to Observables#
Now let’s plot
Recall that
fig, ax = plt.subplots()
ax.plot(yf[0, :], label="y")
ax.plot(xf[0, :], label="x")
ax.legend()
ax.set_title(r"$x$ and $y$")
ax.set_xlabel("Time")
plt.show()
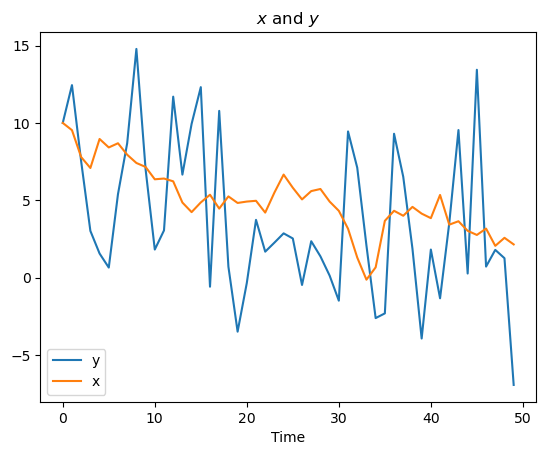
We see above that
3.5.1. Innovations#
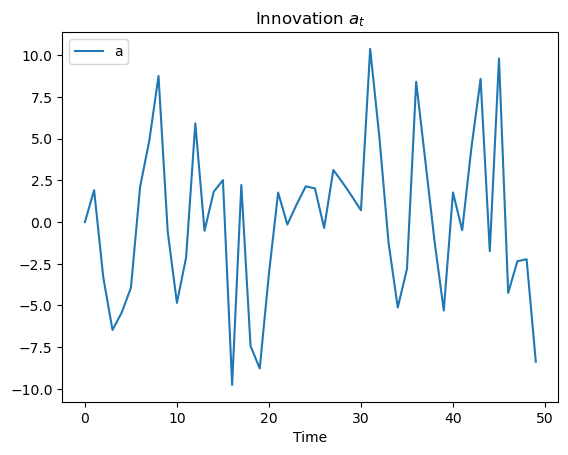
Recall that we wrote down the innovation representation that depended on
fig, ax = plt.subplots()
ax.plot(yf[1, :], label="a")
ax.legend()
ax.set_title(r"Innovation $a_t$")
ax.set_xlabel("Time")
plt.show()
3.6. MA and AR Representations#
Now we shall extract from the Kalman instance kmuth coefficients of
a fundamental moving average representation that represents
a univariate autoregression representation that depicts the coefficients in a linear least square projection of
Then we’ll plot each of them
# Kalman Methods for MA and VAR
coefs_ma = kmuth.stationary_coefficients(5, "ma")
coefs_var = kmuth.stationary_coefficients(5, "var")
# Coefficients come in a list of arrays, but we
# want to plot them and so need to stack into an array
coefs_ma_array = np.vstack(coefs_ma)
coefs_var_array = np.vstack(coefs_var)
fig, ax = plt.subplots(2)
ax[0].plot(coefs_ma_array, label="MA")
ax[0].legend()
ax[1].plot(coefs_var_array, label="VAR")
ax[1].legend()
plt.show()
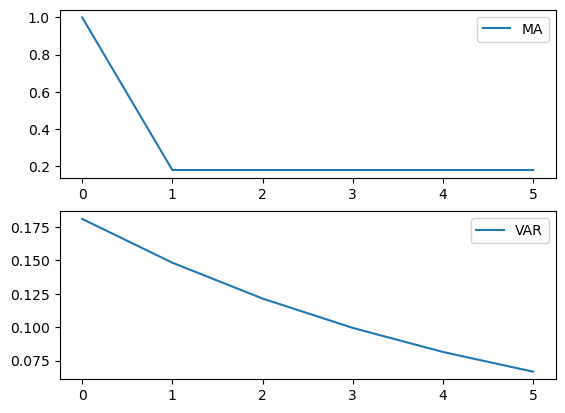
The moving average coefficients in the top panel show tell-tale
signs of
The autoregressive coefficients decline geometrically with decay
rate
These are exactly the target outcomes that Muth (1960) aimed to reverse engineer
print(f'decay parameter 1 - K1 = {1 - K1}')
decay parameter 1 - K1 = 0.8190024875775823